| 思考,快与慢 | 收藏 |
第8章 我们究竟是如何作出判断的?
思考,快与慢 作者:丹尼尔·卡尼曼
你可以回答无数个问题,无论这些问题是别人问你的还是你自问的。同样,你能评价的事物特征也是无数的。你能数出这页中“的”字的出现次数,能比较自己家的窗子和马路对面那家的窗子哪个高,也能对你支持的参议员的政治前景作出评价,其前途无限光明还是前景堪忧,或是碌碌无为。这些问题由系统2来解决,系统2能调动注意力并通过搜寻记忆去寻找答案。系统2接受问题或提出问题:不管是提问还是回答,它都能引导注意力并搜寻记忆来找到答案。系统1以不同的方式运行,不断监视着大脑内外发生的一切,没有特定意图,也无须付出多少努力,只是对当时的情形作出全方位评估。这些“基本的评估”在直觉性判断中扮演了重要角色,因为人们常会拿它们来替代更难的问题—这也是启发法和偏见研究方法的基本理念。系统1其他两个特点也支持用一种判断代替另一种判断的做法。其中一个特点就是系统1具备跨维度解读价值观的能力,你可以回答一个大多数人都觉得很简单的问题:“如果山姆的身高和智商一样,那么他究竟有多高?”此时思维快捷方式便开始运行了。系统2会集中注意力回答某个特定问题,或是对某种情况的特殊属性进行评估,集中的注意力又会自动运行其他的评价程序,包括一些基本判断。
看照片预测竞选胜出者,为何其准确率可高达70%?
随着人类进化不断完善,系统1可以对生物体生存必须解决的主要问题提供一个连续的评估,这些问题包括:事情进展得怎么样了?我们面临的是威胁还是机遇?一切都正常吗?我应该是前进还是退避呢?这些问题也许对于生存在城市中的人而言,不像对大草原上的羚羊那样紧急,但我们有不断进化的遗传神经机制,可以持续不断地对威胁水平进行评估。我们通常用好与坏来评价不同情形,要么说要避开这种情况要么说可以泰然处之,没有问题。人的好心情和认知放松与动物对安全和熟悉程度的判断是相当的。
如果想找一个“基本判断”的典型例子,想想只需一瞥就能区分朋友和敌人的能力就是了。这种能力能够提高人们在危险世界的生存概率,而这种专属能力也在不断增强。我在普林斯顿大学的同事亚历克斯·托多罗夫(Alex Todorov)曾经对与陌生人接触的安全性问题作出快速判断这一能力的生物学根源进行了探索。他认为我们生来就具有判断的能力,只需瞥一眼陌生人的脸,就能对这个人的两点重要事实作出判断:他有多强势(因此存在潜在的威胁性);这个人有多可信(不管他的用意可能是友好的还是充满敌意的)。脸型为判断提供了许多暗示:方下巴就是强势的信号。面部表情(微笑或皱眉)是对陌生人意图的判断提示,方下巴加上瘪嘴唇也许就预示着有麻烦了。看脸形的精确性不是很高:圆下巴并不代表温顺,笑容(在某种程度上)也是可以伪装的。不过,即使对陌生人作出判断的能力不高,具备这种能力也是我们的生存优势。
这种古老的机制在现代社会得到重新利用:它对人们如何选举有些影响。托多罗夫向他的学生展示了一些人脸的图片,有时展示的时间只有0.1秒,他让这些学生按不同属性对这些面部图片进行评估,这些属性包括可爱程度和做事能力。结果所有学生对这些图片的评估结果非常一致。托多罗夫展示给学生的那些人脸图片并不是随意组合的,而是参加竞选的那些政治家的照片。大选结束后,托多罗夫将选举结果和普林斯顿大学学生所作出的能力评估进行了比较,这些学生当时并不了解这些候选人的任何政治背景,仅凭自己对这些照片的匆匆一瞥就作出了评估。事实证明,约有70%的参议员、国会议员和地方长官的竞选活动的胜出者也正是那些在照片评估中获得较高评价的人。这一惊人结果在芬兰的全国大选中得到证实,同样的情况也发生在英国的地区选举中,澳大利亚、德国和墨西哥的众多选举中也发生过类似事件。令人惊奇的是(至少对我而言是这样的),在托多罗夫的研究中,能力评估远比可爱程度的评估对选举结果的预见能力强。
托多罗夫发现,人们总会结合力量和可信度两方面因素来评估一个人的能力。刚毅的方下巴和自信的微笑便可告诉我们,这个人很有能力。没有证据显示这些面部特征确实能预示某些政治家可以当选,但关于人们对胜出和出局候选人的判断研究显示,我们往往在投票前就会对那些不具备我们认可的面部特征的候选人持否定态度。在他的研究中,失败者引起的(负面)情感回应更强烈,我将这个例子称为“判断启发法”案例,接下来的章节中会沿用这个说法。投票者尝试着对候选人将来的任职表现生成一种印象,他们又转而依靠系统2快速自主地作出一种更加简单的判断,这一系统只有在必要时才会作出这一判断。
许多政治学者也循着托多罗夫最初研究的路子继续深入研究这一问题,他们划定了一类投票者,这类投票者往往会不由自主地听从系统1的指挥。这些投票者经常看电视,对政治却所知甚少,而那些政治学者在他们身上找到了自己一直在寻找的东西。不出所料,对于那些信息贫乏、爱看电视的投票者来说,面部特征表现出的能力对其投票的影响较大,其受影响程度约为那些信息丰富、看电视少的投票者的3倍。显然,系统1对投票选择的影响因人而异,下文中我们还会遇到一些体现个体差异性的例子。
当然,系统1理解语言,这种理解是建立在一些基本判断基础之上的,而这些判断通常又是在洞察事实和理解信息的基础上作出的。这些判断包括对相似度和代表性的判断,对因果关系的属性以及对联想和样本的可用性的判断。尽管判断的结果是用来满足任务要求的,但是没有具体任务时,这些判断活动照样也在进行着。
基本判断的内容很多,但并不是每个可能的属性都需要判断。例如,我们可以简单看看图7。
一眼看去,你便会对该图的很多特征有个初步印象。你知道左右两个长方体一样高,也很相似。然而,左边那个长方体的方块数和铺在平面上的方块数是不是一样,这可不是瞥一眼就能明了的事,而且你也想不出这堆方块能摞成多高的长方体。
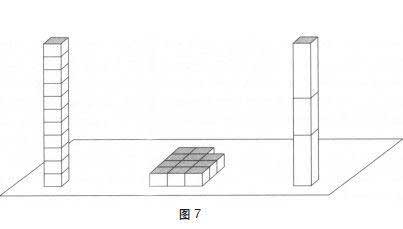
为了证实左面长方体的方块数目和中间的方块数目相同,你需要数一下这两堆方块,对比一下结果,这个活动只有系统2能完成。
平均长度与总长度是完全不同的数量概念
还有一个例子,请看这个问题:图8中各条线的平均长度是多少?
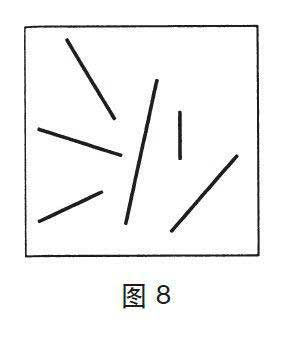
这个问题很简单,系统1无须任何提示就能回答。实验显示,人们在不到一秒钟的时间里完全可以精确地记下很多线段的平均长度。此外,观察者的认知系统即使正忙于记忆,这些判断的精确度也不会受到影响。认知系统未必知道如何用英寸或厘米为单位来描述平均值,但是如果让其判断另外一条线是否符合平均值,它们的判断也是非常精确的。对于一组线的长度标准生成一个印象无须系统2的参与,系统1会自主且毫不费力地完成这一任务,就像它记一组线的颜色和它们之间不相平行的事实一样轻松。我们也可以立刻对众多物品的数量生成一个印象,如果其数量只有4个或少于4个的话,印象会很精确;如果更多的话,就会变得模糊。
现在我们来讨论另外一个问题:图8中所有线的总长度是多少?这是一种全新体验,因为系统1无法为回答这个问题提供建议。为此题作答的唯一办法就是启动系统2,系统2会尽力估计平均值,评估或数出有几条线,用平均长度去乘条数得出结果。
仅凭一瞥系统1计算出一组线的总长度,其结果多半不对,这一点你很清楚。你认为自己绝不会这样做。事实上,这是该系统一个重要的局限性。因为系统1通过原型或一组典型事例来代表不同事物分类,它能解决好平均问题,但对总量问题就束手无策了。一个类别的规模及其所包含的实例数量,在我们判断总额变量时常常被忽略掉了。
在我们进行的众多实验中,有一项是根据那次损失惨重的埃克森–瓦尔德斯号(Exxon Valdez)原油泄漏事件的诉讼而设计的,我们询问受试者是否愿意掏钱买网来覆盖油池,因为这些油池常淹死迁徙的鸟类。受试者组成的不同小组分别表明了各组的意愿,他们愿意掏钱来拯救鸟的数量分别为2000只、20000只和200000只。如果拯救鸟类是个经济善举的话,其价值大小就要看总数这一变量了,即拯救200000只鸟应该比拯救2000只鸟更有价值。事实上,3个组的平均捐款分别是80美元、78美元和88美元,与鸟的数量没有什么关系。3组受试者做出反应的对象为原型—一只无助的小鸟被淹死的可怕画面,鸟的羽毛浸泡在黏稠的原油中。实验人员屡次发现,在这样的情形下,受试者几乎完全忽略了数量的概念。
与强度等级匹配的描述
诸如你的幸福感、总统受欢迎的程度、金融骗子的合理惩罚和政治家的未来前景等问题有一个共同的重要特点:这些问题都涉及隐含的强度或数量概念,因而我们也就可以使用“更”这个词对其进行描述:更幸福、更受欢迎、更严厉或(对政治家来说)更有力度。例如,一个候选人的政治前景可能是“她在首轮竞选就会出局”这样的背运,也可能是“她有朝一日会成为美国总统”,身居高位。
接下来我们会了解到系统1的又一新能力。强度的等级在不同领域中都有“匹配”描述。如果罪行是颜色,杀人就应该是深红,颜色比偷窃更深。如果犯罪用音乐来表达,大屠杀就应该用强音,而停车不付钱则应该用弱音。当然,你对惩罚的强度也有类似的感觉。在传统的实验中,有些人用声音的大小来表达犯罪的严重性;其他人用声音大小来表达法律惩罚的严重性。如果你听到了两个声音,一个是表达犯罪的,一个是表达惩罚的,如果一个声音比另一个声音更响的话,你会有不公平之感。
请思考这个例子(后文中还会提到这个例子):
朱莉4岁时就能阅读。
现在请将朱莉这个孩子的阅读能力与下面的强度等级进行匹配:
若某人的身高和朱莉的早慧程度一样,那他有多高?
你觉得6英尺[1英尺=0.304 8米。——译者注]怎么样?显然太少了。那7英尺呢?也许又太多了。你希望找到一个高度能匹配4岁孩子极强的能力。虽然很强,但并不超群。15个月大就能阅读才是超群的能力,这就跟一个人身高7.8英尺一样。
你的工作收入多高才能与朱莉的阅读能力相匹配呢?
什么罪行的严重程度可以与朱莉的早慧程度相匹配呢?
常春藤大学的毕业学分积点多高才能与朱莉的阅读水平相匹配呢?
上述问题并不是很难回答,对吧?此外,可以肯定的是与你同处一个文化领域的人作出的匹配与你的回答会很相近。我们发现,人们根据朱莉的阅读年龄这一信息预估她的学分积点时,他们通过一种范畴向另一范畴的转换来回答这个问题,并且选出了相应的学分积点值。我们也明白为什么这种利用匹配进行预测的模式从统计学角度来看是错误的,尽管对于系统1来说这很正常,但对于统计学家以外的大多数人来说,系统2也可以接受这种做法。
思维的发散性让我们作出直觉性判断
系统1任何时候都可以同时进行多种估算,其中有些估算是持续不间断的常规评估。只要眼睛是睁开的,你的大脑就会对视觉范围内呈现出的立体事物进行评估,这种评估是对这些物体的形状、空间位置和特性等因素的全方位评价。这一评估活动的运行或对违背期望的事物进行持续监督的行为都是无意识的。与这些常规评估不同,其他评估行为只有在需要时才会进行:你不会持续评估自己有多高兴或多富裕,即使热衷政治,你也不会一直不间断地评估总统的执政前景。偶尔的判断是主观自愿的,这种判断才是有意识的。
你不会不由自主地数出每个读到的词的音节数,但如果你选择这样做,就能数对。不过,想要使刻意计算的结果很精确并非易事:我们计算的结果往往比自己想要的或需要的要多。这种过量计算的过程就体现了“思维的发散性”。如同想用散弹猎枪瞄准一个点是不可能的一样(它射出的子弹是分散的),想要让系统1完全执行系统2的命令且不做多余的工作也很难,这一点与散弹枪很相似。我很久以前从书上看到的两个实验就表明了这一点。
其中一个实验让受试者听几对词,若他们听出这些词是押韵的,要马上按下一个键。下面两组词都是押韵的:
VOTE–NOTE
VOTE–GOAT
在你看来,区别很明显,因为你看到了这两组词,而受试者只能听到单词。“VOTE”和“GOAT”押韵,但它们的拼写不同,虽然受试者听到了这两个词,但他们也会受到拼写的影响。如果两个词的拼写不同,受试者听出它们是押韵的速度就会慢些。尽管要求是比较声音,但受试者同时也对两者的拼写进行了比较,而且与声音无关的不匹配因素妨碍他们迅速作出判断。刻意回答一个问题却引起了另一个问题,这一行为不仅没必要,而且对主要任务的完成也很不利。
在另一项实验中,受试者听了几个句子,如果句子是真实的,就要马上按下一个键,如果是假的,就按下另一个键。对以下这些句子的正确回应是什么呢?
有些路是蛇形的。
有些工作是蛇。
有些工作像监狱。
这三个句子从表述上来看都是错的。不过,你很可能已经注意到了第二个句子比另两个句子错得更明显,实验也证实了这一本质性不同。之所以存在这种不同,是因为第一句、第三句两个难句从比喻角度看是正确的。这次又是要进行一个预估活动却引起了另一个预估行为,而且,正确答案在冲突中更明显,但这个与回答并不相关的冲突却影响了系统的正常运行。在下一章中我们会发现,思维的发散性和强度匹配结合起来就可以解释为什么我们对很多自己不很了解的事情能够作出直觉性判断。
示例—判断问题
“评价一个人是否有吸引力是一种基本判断,不管你是否想这样做,这种评价都是不由自主进行的,也会对你产生影响。”
“我们的大脑中有一些线路,这些线路可以从脸型来推断一个人统领大局的能力,即他看上去有些领导气质。”
“如果强度与罪行不匹配,惩罚则不可能公正。就像是你可以用光的亮度来与音量的大小匹配一样。”
“关于思维的发散性,有这样一个明确的例子:他被问及是否认为这家公司财力雄厚时,他想到的却是该公司令其钟情的产品。”